I am trying to get the Training application to work.
As model training is about to start I get the following error:
2020-03-03 16:08:23 (INFO) TrainImagesClassifier: Model training...
2020-03-03 16:08:23 (INFO) TrainImagesClassifier: Reading vector file 1/1
2020-03-03 16:08:23 (FATAL) TrainImagesClassifier: Caught std::exception during application execution: stod
I assume its a issue with the formatting of an input parameter for one of the float values, but I can’t see it.
Similar issues had problems with unicode characters and space, the first of which I do not have, and as for the latter, I tested it with a path without spaces and it still had the same issue. Even then, I doubt the space is an issue, since it gets through the preliminary stuff just fine, and even recognizes the fields available in the shapefile as expected.
My intention was to use the Python API, with the Conda repo, but since the build is a 7.1.0rc, I used the 7.0.0 cli to check, but I still have the same issue. Python code is down below, but I’ll start with cli.
CLI (OTB 7.0.0)
Testing with non-existent field (Outputs all existing fields, for reference)
$ otbcli_TrainImagesClassifier \
> -io.il "/mnt/hgfs/Storage/Documents/Image Classification/Stacked/stacked.tif" \
> -io.vd "/mnt/hgfs/Storage/Documents/Image Classification/Shapefiles/learn.shp" \
> -sample.vfn codeess \
> -sample.vtr 0.0 \
> -classifier rf \
> -classifier.rf.max 25 \
> -io.out "/mnt/hgfs/Storage/Documents/Image Classification/Stacked/model.rf"
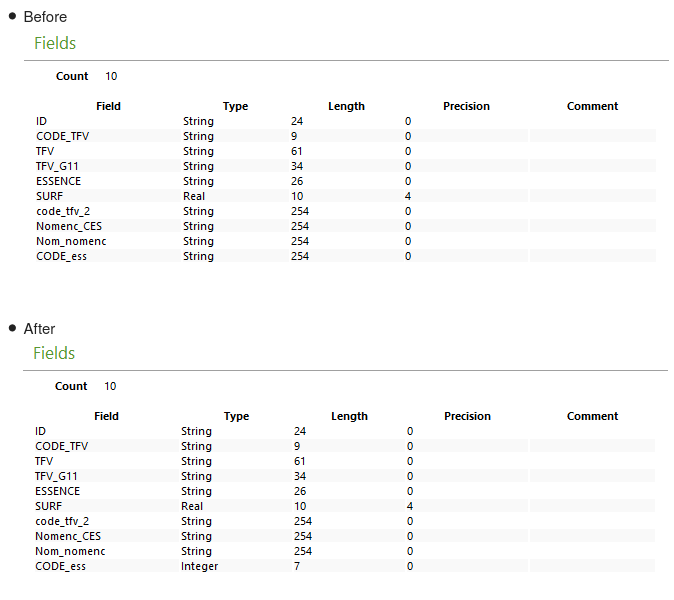
2020-03-03 16:03:11 (FATAL) TrainImagesClassifier: itk::ERROR: ListViewParameter(0x827a90): Value codeess not found in the list of choices: ID, CODE_TFV, TFV, TFV_G11, ESSENCE, code_tfv_2, Nomenc_CES, Nom_nomenc, CODE_ess.
I had done this because the python api “works” if I provide the field in lowercase and with no underscore. I might have not read the documentation, and not particularly concerned about it, just to point it out
Actual Implementation
otbcli_TrainImagesClassifier \
-io.il "/mnt/hgfs/Storage/Documents/Image Classification/Stacked/stacked.tif" \
-io.vd "/mnt/hgfs/Storage/Documents/Image Classification/Shapefiles/learn.shp" \
-sample.vfn CODE_ess \
-sample.vtr 0.0 \
-classifier rf \
-classifier.rf.max 25 \
-io.out "/mnt/hgfs/Storage/Documents/Image Classification/Stacked/model.rf"
Full CLI Output
2020-03-03 16:03:27 (INFO) TrainImagesClassifier: Default RAM limit for OTB is 256 MB
2020-03-03 16:03:27 (INFO) TrainImagesClassifier: GDAL maximum cache size is 396 MB
2020-03-03 16:03:27 (INFO) TrainImagesClassifier: OTB will use at most 8 threads
2020-03-03 16:03:28 (INFO) TrainImagesClassifier: Polygon analysis...
2020-03-03 16:03:28 (INFO) TrainImagesClassifier: Elevation management: setting default height above ellipsoid to 0 meters
2020-03-03 16:03:28 (INFO): Estimated memory for full processing: 27592.9MB (avail.: 256 MB), optimal image partitioning: 108 blocks
2020-03-03 16:03:28 (INFO): Estimation will be performed in 109 blocks of 10980x101 pixels
Analyze polygons...: 100% [**************************************************] (40s)
2020-03-03 16:04:08 (INFO) TrainImagesClassifier: Sampling rates...
2020-03-03 16:04:08 (INFO) TrainImagesClassifier: Sampling strategy : fit the number of samples based on the smallest class
2020-03-03 16:04:08 (INFO) TrainImagesClassifier: Sampling rates for image 1 : className requiredSamples totalSamples rate
1111100 183 1321599 0.000138469
1113100 183 1730 0.10578
1114111 183 85373 0.00214353
1115000 183 12527 0.0146084
1116000 183 97413 0.0018786
1117000 183 55220 0.00331402
1125000 183 3691622 4.95717e-05
1130000 183 96827 0.00188997
1211000 183 817767 0.00022378
1213000 183 12432 0.0147201
1216000 183 183 1
1225000 183 15952 0.0114719
1230000 183 288 0.635417
1381100 183 563297 0.000324873
1390000 183 7329 0.0249693
2000000 183 142900 0.00128062
4000000 183 95736 0.00191151
5000000 183 5963 0.0306893
2020-03-03 16:04:08 (INFO) TrainImagesClassifier: Sample selection...
2020-03-03 16:04:08 (INFO) TrainImagesClassifier: Elevation management: setting default height above ellipsoid to 0 meters
2020-03-03 16:04:08 (INFO) TrainImagesClassifier: Sampling strategy : set number of samples for each class
2020-03-03 16:04:08 (INFO) TrainImagesClassifier: Sampling rates : className requiredSamples totalSamples rate
1111100 183 1321599 0.000138469
1113100 183 1730 0.10578
1114111 183 85373 0.00214353
1115000 183 12527 0.0146084
1116000 183 97413 0.0018786
1117000 183 55220 0.00331402
1125000 183 3691622 4.95717e-05
1130000 183 96827 0.00188997
1211000 183 817767 0.00022378
1213000 183 12432 0.0147201
1216000 183 183 1
1225000 183 15952 0.0114719
1230000 183 288 0.635417
1381100 183 563297 0.000324873
1390000 183 7329 0.0249693
2000000 183 142900 0.00128062
4000000 183 95736 0.00191151
5000000 183 5963 0.0306893
2020-03-03 16:04:08 (INFO): Estimated memory for full processing: 27592.9MB (avail.: 256 MB), optimal image partitioning: 108 blocks
2020-03-03 16:04:08 (INFO): Estimation will be performed in 121 blocks of 1056x1056 pixels
Selecting positions with periodic sampler...: 100% [**************************************************] (1m 07s)
2020-03-03 16:05:15 (INFO) TrainImagesClassifier: Sample extraction...
2020-03-03 16:05:49 (INFO): Estimated memory for full processing: 41390MB (avail.: 256 MB), optimal image partitioning: 162 blocks
2020-03-03 16:05:49 (INFO): Estimation will be performed in 162 blocks of 10980x68 pixels
Extracting sample values...: 100% [**************************************************] (2m 33s)
2020-03-03 16:08:23 (INFO) TrainImagesClassifier: Model training...
2020-03-03 16:08:23 (INFO) TrainImagesClassifier: Reading vector file 1/1
2020-03-03 16:08:23 (FATAL) TrainImagesClassifier: Caught std::exception during application execution: stod
Python (Conda Package: otb 7.1.0.rc1 py37hf484d3e_0)
Path Setup
param = {'il': [join(path['stacked'], "stacked.tif")],
'vd': [join(path['shapefiles'], "learn.shp")],
'out': join(path['stacked'], "model.rf")
}
for p in param:
print(p, param[p])
il ['/mnt/hgfs/Storage/Documents/Image Classification/Stacked/stacked.tif']
vd ['/mnt/hgfs/Storage/Documents/Image Classification/Shapefiles/learn.shp']
out /mnt/hgfs/Storage/Documents/Image Classification/Stacked/model.rf
Actual Implementation
app = otbApplication.Registry.CreateApplication("TrainImagesClassifier")
# Input data
app.SetParameterStringList("io.il", [join(path['stacked'], "stacked.tif")])
app.SetParameterStringList("io.vd", [join(path['shapefiles'], "learn.shp")])
# Update Parameters using input files
app.UpdateParameters()
# Training samples parameters
app.SetParameterFloat("sample.vtr", 0.0)
app.SetParameterString("sample.vfn", "codeess") # Lower Case + Remove '_'
app.SetParameterString("classifier","rf")
app.SetParameterInt("classifier.rf.max", 25)
# Output data
app.SetParameterString("io.out", join(path['stacked'], "model.rf"))
app.ExecuteAndWriteOutput()
Python Output
2020-03-03 15:41:28 (INFO) TrainImagesClassifier: Default RAM limit for OTB is 256 MB
2020-03-03 15:41:28 (INFO) TrainImagesClassifier: GDAL maximum cache size is 396 MB
2020-03-03 15:41:28 (INFO) TrainImagesClassifier: OTB will use at most 8 threads
2020-03-03 15:41:29 (INFO) TrainImagesClassifier: Polygon analysis...
2020-03-03 15:41:29 (INFO) TrainImagesClassifier: Elevation management: setting default height above ellipsoid to 0 meters
2020-03-03 15:41:29 (INFO): Estimated memory for full processing: 27592.9MB (avail.: 256 MB), optimal image partitioning: 108 blocks
2020-03-03 15:41:29 (INFO): Estimation will be performed in 109 blocks of 10980x101 pixels
Analyze polygons...: 100% [**************************************************] (40s)
2020-03-03 15:42:10 (INFO) TrainImagesClassifier: Sampling rates...
2020-03-03 15:42:10 (INFO) TrainImagesClassifier: Sampling strategy : fit the number of samples based on the smallest class
2020-03-03 15:42:10 (INFO) TrainImagesClassifier: Sampling rates for image 1 : className requiredSamples totalSamples rate
1111100 183 1321599 0.000138469
1113100 183 1730 0.10578
1114111 183 85373 0.00214353
1115000 183 12527 0.0146084
1116000 183 97413 0.0018786
1117000 183 55220 0.00331402
1125000 183 3691622 4.95717e-05
1130000 183 96827 0.00188997
1211000 183 817767 0.00022378
1213000 183 12432 0.0147201
1216000 183 183 1
1225000 183 15952 0.0114719
1230000 183 288 0.635417
1381100 183 563297 0.000324873
1390000 183 7329 0.0249693
2000000 183 142900 0.00128062
4000000 183 95736 0.00191151
5000000 183 5963 0.0306893
2020-03-03 15:42:10 (INFO) TrainImagesClassifier: Sample selection...
2020-03-03 15:42:10 (INFO) TrainImagesClassifier: Elevation management: setting default height above ellipsoid to 0 meters
2020-03-03 15:42:10 (INFO) TrainImagesClassifier: Sampling strategy : set number of samples for each class
2020-03-03 15:42:10 (INFO) TrainImagesClassifier: Sampling rates : className requiredSamples totalSamples rate
1111100 183 1321599 0.000138469
1113100 183 1730 0.10578
1114111 183 85373 0.00214353
1115000 183 12527 0.0146084
1116000 183 97413 0.0018786
1117000 183 55220 0.00331402
1125000 183 3691622 4.95717e-05
1130000 183 96827 0.00188997
1211000 183 817767 0.00022378
1213000 183 12432 0.0147201
1216000 183 183 1
1225000 183 15952 0.0114719
1230000 183 288 0.635417
1381100 183 563297 0.000324873
1390000 183 7329 0.0249693
2000000 183 142900 0.00128062
4000000 183 95736 0.00191151
5000000 183 5963 0.0306893
2020-03-03 15:42:10 (INFO): Estimated memory for full processing: 27592.9MB (avail.: 256 MB), optimal image partitioning: 108 blocks
2020-03-03 15:42:10 (INFO): Estimation will be performed in 121 blocks of 1056x1056 pixels
Selecting positions with periodic sampler...: 100% [**************************************************] (1m 00s)
2020-03-03 15:43:10 (INFO) TrainImagesClassifier: Sample extraction...
2020-03-03 15:43:44 (INFO): Estimated memory for full processing: 41390MB (avail.: 256 MB), optimal image partitioning: 162 blocks
2020-03-03 15:43:44 (INFO): Estimation will be performed in 162 blocks of 10980x68 pixels
Extracting sample values...: 100% [**************************************************] (2m 40s)
2020-03-03 15:46:25 (INFO) TrainImagesClassifier: Model training...
2020-03-03 15:46:25 (INFO) TrainImagesClassifier: Reading vector file 1/1
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-14-33ce57493a38> in <module>
27 app.SetParameterString("io.out", param['out'])
28
---> 29 app.ExecuteAndWriteOutput()
~/anaconda3/envs/orfeo/lib/otb/python/otbApplication.py in ExecuteAndWriteOutput(self)
2799
2800 def ExecuteAndWriteOutput(self):
-> 2801 return _otbApplication.Application_ExecuteAndWriteOutput(self)
2802
2803 def ConnectImage(self, arg2, app, out):
RuntimeError: stod